予測符号化とリザバー計算を統合した多感覚統合モデルを提案 ― ノイズに強い音声認識を実証
私たちは騒がしい環境でも、相手の発話内容を比較的正確に理解することができます。その背景には、音声だけでなく話者の口の動きなどの視覚情報を同時に利用する「多感覚統合」の仕組みがあります。本研究では、この脳の情報処理機構を数理モデルとして構築し、騒音環境下でも安定して動作する音声認識モデルを開発しました。
本成果は Frontiers in Computational Neuroscience に掲載されています。
研究の背景
多感覚統合は、視覚や聴覚など複数の感覚情報を統合し、より信頼性の高い知覚を形成する脳の基本機能です。特に音声知覚においては、聴覚情報が劣化した場合でも視覚情報が補完的に働き、認識精度が向上することが知られています。
この現象はベイズ的信頼度重みづけ理論や予測符号化理論によって説明されてきましたが、階層的皮質構造を反映しつつ、時間的に変化する信号を扱い、さらに感覚信号の信頼性を動的に調整する統合的な神経回路モデルは十分に整備されていませんでした。
本研究のアプローチ
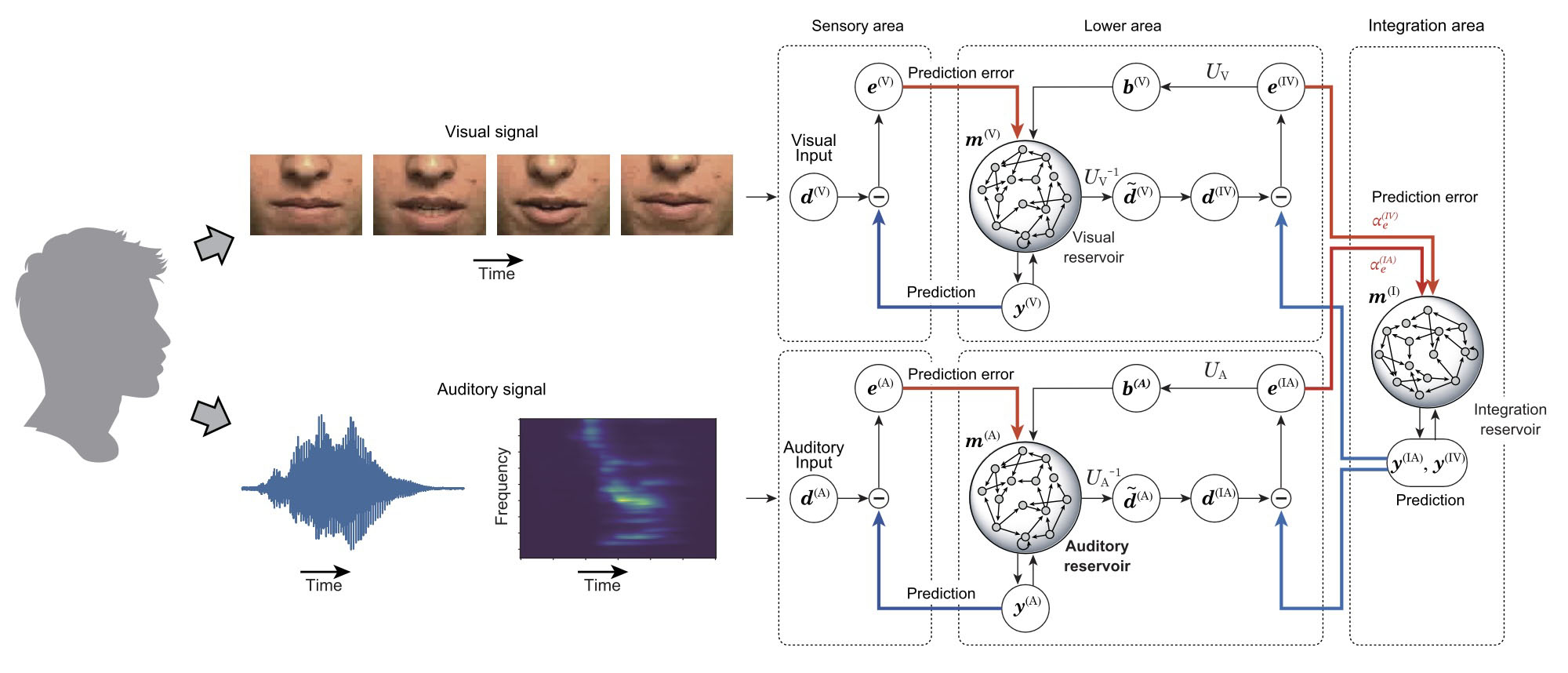
本研究では、予測符号化理論に基づく階層構造に再帰型ネットワーク(リザバー計算)を組み込むことで、多感覚統合を実現するモデルを構築しました。
予測符号化の枠組みでは、上位領域が下位領域の状態を予測し、下位領域は予測誤差を上位へ返します。ネットワーク全体はこの誤差を最小化する方向へと内部状態を更新します。本研究では、この各領域内部をランダム再帰結合ネットワークで構成しました。リザバー計算は、時間的に変化する信号を内部ダイナミクスとして保持できる特徴を持ち、音声のような時系列データ処理に適しています。
さらに重要なのは、感覚信号の信頼性を予測誤差フィードバックの強度として実装した点です。聴覚ノイズが増大した場合には、聴覚予測誤差の重みを抑制し、視覚情報の寄与を相対的に高めることで、状況に応じた適応的な統合を可能にしました。
実験結果
数字音声(0〜9)と話者の口元映像を用いたマルチモーダル音声認識課題において、聴覚信号に段階的にノイズを付加し、モデルの認識精度を評価しました。
その結果、聴覚単独モデルではノイズの増加に伴い精度が大きく低下する一方で、視覚情報を統合したモデルは高い認識精度を維持しました。さらに、ノイズが強い条件ほど統合による性能向上が顕著になるという「逆効果性(inverse effectiveness)」の特徴を再現しました。
また、リザバー内部状態からの読み出しは、センサ信号を直接回帰する方法よりも安定した認識性能を示しました。これは再帰ダイナミクスが音声の時間構造を内部表現として保持していることを示唆します。
加えて、予測誤差の移動平均を用いてノイズ強度を推定し、フィードバック強度を動的に調整する適応機構を実装しました。時間的に変動するノイズ環境においても認識性能を維持できることを確認しています。
学術的意義と今後の展望
本研究は、ベイズ的信頼度理論、予測符号化理論、そしてリザバー計算という三つの枠組みを統合し、多感覚統合の神経ダイナミクス的実装可能性を示しました。特に、ランダム再帰構造が多感覚統合を支える共通皮質基盤となり得る可能性を示唆した点は、理論神経科学および脳型AI研究の双方において意義があります。
今後は、スパイキングニューロンモデルへの拡張や局所可塑性の導入、より深い階層構造の検討などを進め、より生理学的妥当性の高いモデルへ発展させる予定です。また、ノイズ適応型マルチモーダルAIやロボティクス応用への展開も視野に入れています。
論文情報
Yonemura, Y., & Katori, Y. (2024). Dynamical predictive coding with reservoir computing performs noise-robust multi-sensory speech recognition. Frontiers in Computational Neuroscience.
https://www.frontiersin.org/journals/computational-neuroscience/articles/10.3389/fncom.2024.1464603